主页 > imtoken钱包app教程 > 【学习笔记】比特币交易的数据结构
【学习笔记】比特币交易的数据结构
/**
* An outpoint - a combination of a transaction hash and an index n into its
* vout.
*/
class COutPoint {
private:
TxId txid; // 交易哈希
uint32_t n; // 输出的序号
......
};
输入有一个 4 字节的 nSequence 字段,将在后面的文章中讨论。
贸易
/**
* The basic transaction that is broadcasted on the network and contained in
* blocks. A transaction can contain multiple inputs and outputs.
*/
class CTransaction {
public:
const int32_t nVersion; // 交易结构的版本标识,4 字节
const std::vectorvin; // 输入数组
const std::vectorvout; // 输出数组
const uint32_t nLockTime;
......
private:
const uint256 hash; // 交易的哈希
......
};
事务有一个 4 字节的 nLockTime 字段,将在后面的文章中讨论。
序列化和反序列化
在程序中,通常使用特定的数据结构来表示和存储特定的数据,如上所述。
这样的数据便于人们识别和理解,便于程序操作,但不方便在网络上传输。
在传输之前,需要将数据结构转换成便于网络传输的字节流形式。这个过程称为序列化。
将字节流中的数据“恢复”到数据结构中是一个称为反序列化的过程。
为了便于理解,举了一个例子。我们可以定义以下数据结构来表示二十四小时制的时间。
Type Time {
uint32_t hour;
uint32_t minute;
uint32_t second;
};
时、分、秒用 4 字节整数表示,20:35:10 可以表示为
Time t;
t.hour = 20; // 00 00 00 14
t.minute = 35; // 00 00 00 23
t.second = 10; // 00 00 00 0a
注释后面是数据的十六进制表示。传输数据时,发送
00 00 00 14 00 00 00 23 00 00 00 0a
并规定:

对方接收到数据后比特币中的数据存储系统,可以按照规则将字节流恢复为数据结构的形式。
注意,数据结构不仅包含数据的值,还描述了“这是什么数据”。
当您看到 t.hour = 20 时,您就知道该数据代表时间上的“小时”,值为 20。
但是当你看到 00 00 00 14 时,你只知道这个数据的值是 20,但你不知道这是 20 小时、20 分钟还是 20 秒。因此,有必要定义序列化规则。
还有一点不容易注意到的是比特币中的数据存储系统,需要多字节表示的数据项的值(“小时”字段为4字节)在字节流中是如何排列的。
在上面的示例中,您按顺序收到前 4 个字节
00
00
00
14
默认情况下,首先收到的字节是数据的高字节,最后收到的字节是低字节,所以你得到 00 00 00 14。
也就是说,如果对方认为最先收到的字节是数据的低位字节,那么他会将数据解析成14 00 00 00,从而导致错误。
因此,在传输字节流时,还需要定义字节的排列方式。这是另一个非常有趣的话题,称为 Endianness。以下是一些信息和讨论。
在比特币系统中,除解锁脚本和加锁脚本外,其他部分均采用little-endian方式编码,最先收到的字节被认为是数据的低位字节。
如果我们刚才以小端模式传输数据,字节流应该是
14 00 00 00 23 00 00 00 0a 00 00 00
序列化输出
输出序列化后,格式如下。
长度(字节)描述

8
以聪为单位的货币价值
1~9 变量整数
后面的lock脚本,有多少字节
加长
锁定脚本内容
对于以下序列化交易输出,
60e31600000000001976a914ab68025513c3dbd2f7b92a94e0581f5d50f654e788ac
可以反序列化为
序列化输入
输入序列化后,格式如下。
长度(字节)描述
32
引用的交易哈希,UTXO 来自哪个交易
4
引用输出的序号,UTXO是该交易的第一个输出,从0开始计数

1~9 变量整数
后面的解锁脚本有多少字节
加长
解锁脚本内容
4
序列
对于以下序列化的交易输入(我添加了换行符以便于识别),
186f9f998a5aa6f048e51dd8419a14d8a0f1a8a2836dd734d2804fe65fa35779
00000000
8b
483045022100884d142d86652a3f47ba4746ec719bbfbd040a570b1deccbb6498c75c4ae24cb02204b9f039ff08df09cbe9f6addac960298cad530a863ea8f53982c09db8f6e381301410484ecc0d46f1918b30928fa0e4ed99f16a0fb4fde0735e7ade8416ab9fe423cc5412336376789d172787ec3457eee41c04f4938de5cc17b4a10fa336a8d752adf
ffffffff
可以反序列化为
序列化交易
交易由输入和输出组成。交易序列化后,格式如下。
长度(字节)描述
4
交易结构版本
1~9 变量整数
交易包含多个输入,非零正整数

加长
输入数组
1~9 变量整数
交易包含多个输出,非零正整数
加长
输出数组
4
nLockTime
你注意到不,在交易被序列化之后,交易哈希就没有了。
只需对序列化的交易数据进行哈希运算,即可得到交易的哈希值。这种冗余信息不需要传输。
通过以下过程,计算出交易的哈希值。
对序列化的交易数据进行SHA256运算,得到S1 对S1进行SHA256运算,得到S2,按字节翻转S2,得到交易的hash
Alice去Bob的咖啡店支付0.015比特币买咖啡,产生了一笔交易
0627052b6f28912f2703066a912ea577f2ce4da4caa5a5fbd8a57286c345c2f2
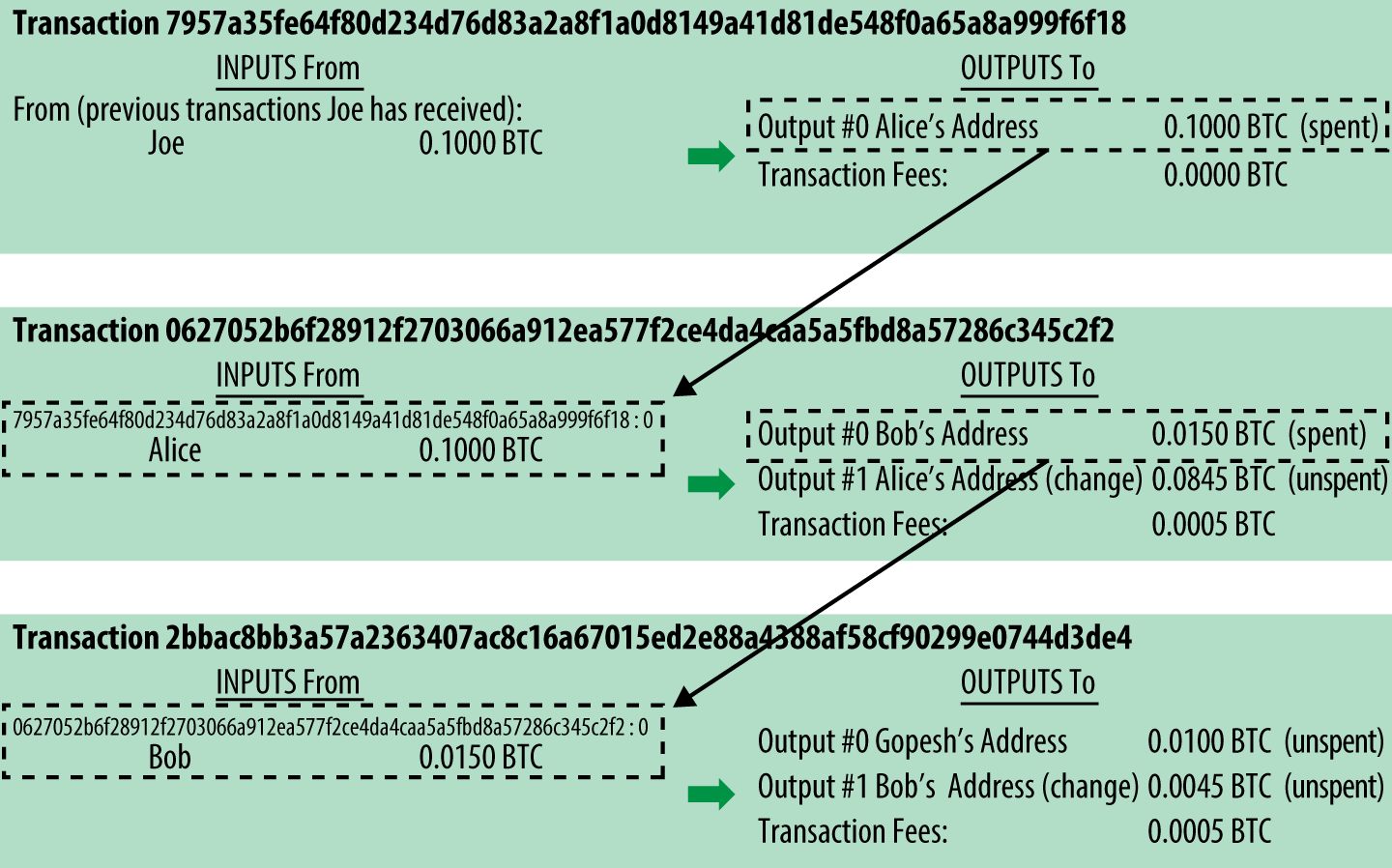
这是序列化后事务的样子(我为你添加了换行符),你能找到每个字段的信息吗?

01000000
01
186f9f998a5aa6f048e51dd8419a14d8a0f1a8a2836dd734d2804fe65fa35779
00000000
8b
483045022100884d142d86652a3f47ba4746ec719bbfbd040a570b1deccbb6498c75c4ae24cb02204b9f039ff08df09cbe9f6addac960298cad530a863ea8f53982c09db8f6e381301410484ecc0d46f1918b30928fa0e4ed99f16a0fb4fde0735e7ade8416ab9fe423cc5412336376789d172787ec3457eee41c04f4938de5cc17b4a10fa336a8d752adf
ffffffff
02
60e3160000000000
19
76a914ab68025513c3dbd2f7b92a94e0581f5d50f654e788ac
d0ef800000000000
19
76a9147f9b1a7fb68d60c536c2fd8aeaa53a8f3cc025a888ac
00000000
点击下方链接,体验计算交易哈希的过程。
对序列化的交易数据做SHA256得到S1的值
dda380359b9d149fbc48d95aebbbe59117d91fb19e00d13f8992b38ada9654be
对 S1 做 SHA256 得到 S2 的值
f2c245c38672a5d8fba5a5caa44dcef277a52e916a0603272f91286f2b052706
逐字节翻转S2得到交易的hash
0627052b6f28912f2703066a912ea577f2ce4da4caa5a5fbd8a57286c345c2f2
还有一点需要注意的是,虽然 Coinbase 交易不需要输入,但输入数组仍然存在于结构体中(长度为 1),并且输入结构体中的每个字段也会被设置为一个特殊的值进行识别。
交易 d0ec21e1d73d06be76c2b5b1e5ec486085bda8264229046c11b95f66f2eded83 是 Coinbase 交易,其序列化内容如下。
01000000
01 <== 输入数组的长度为 1
0000000000000000000000000000000000000000000000000000000000000000 <== 引用的交易哈希全为 0
ffffffff <== 引用的输出序号全为 f
45
03ec59062f48616f4254432f53756e204368756e2059753a205a6875616e67205975616e2c2077696c6c20796f75206d61727279206d653f2f06fcc9cacc19c5f278560300
ffffffff
01
529c6d9800000000
19
76a914bfd3ebb5485b49a6cf1657824623ead693b5a45888ac
00000000
还有一件事
有没有注意到,在序列化规则中,描述脚本长度的字段长度和数组的个数也发生了变化。
60e3160000000000 19 76a914ab68025513c3dbd2f7b92a94e0581f5d50f654e788ac
这是刚才的例子。60e3160000000000的前8个字节表示币值确定,因为规则定义币值用8个字节表示。
但是,“锁定脚本大小”字段的长度是不确定的,可以用 1 到 9 个字节表示。
为什么我们可以确定后面的lock脚本的长度是19,而不是76 19?欢迎留言。
参考